How to Summarize Large Documents using Langchain and OpenAI in Python

Computer Science Student
Introduction
In today's fast-moving world where we're bombarded with lots of written information every day, it can feel overwhelming. Whether you're a researcher going through a stack of complicated research papers, someone in charge of organizing a big collection of data, or a student dealing with long articles, one important skill is to be able to take all that information and make it shorter and easier to understand.
In this blog post, we're going to explore how to do that using some really good tools like Langchain and OpenAI. We will use OpenAI’s API for large language models like text-davinci, GPT-3.5, etc. for summarizing our documents. Langchain is a framework in Python that helps in building applications with large language models. By the end of this tutorial, you'll have the knowledge and tools to tackle large volumes of text efficiently.
Use Cases
Document summarization is not a new idea. It's like a handy tool that can be used in many different areas. Let's look at some examples of how document summarization can be really helpful in different situations:
If you run a website with lots of articles, document summarization can help you automatically choose and summarize articles, so your readers quickly see the latest news, making content management easier and more engaging.
For researchers and academics dealing with lots of papers and studies, document summarization can make it easier to find important research details, methods, and conclusions, speeding up their literature reviews and keeping them updated on the latest advancements in their field.
Educators can use document summarization to make study materials, lesson plans, and lecture notes by simplifying long textbooks into short summaries, helping students learn and understand complex topics more easily.
Search engines and information systems can use document summarization to show users short, relevant snippets from documents, making it easier for users to find the information they want and improving their experience.
These are just a few ways document summarization can improve work in different industries. As we get into the technical details of summarization with Langchain and OpenAI, think about how you can use this tool for your own needs.
Prerequisites
Before we start our adventure into the world of document summarization with Langchain and OpenAI, let's make sure you have everything you need. It's pretty straightforward!
I expect you to have some working experience with Python and Python installed on your computer.
You'll want a text editor to write and run your Python code. If you have a favorite one, that's great! If not, I suggest using VS Code.
Knowing about APIs is handy, but it's not mandatory. If you're not familiar with them, still no issues.
So, whether you're a Python expert or just starting, and whether APIs sound confusing or not, you're good to go. Let's get started! 🚀📜
Summarization with Chat-GPT and Its Limitations
In today's world, Chat GPT by OpenAI is a well-known tool with versatile capabilities, such as content generation, language translation, text summarization, programming assistance, and storytelling. However, there's a limit to how much text you can feed into Chat GPT at once, which is approximately 4096 tokens, where a token can be a word, sub-word, character, or punctuation. You can check your text's token count using this online tokenizer.
So, when you need to summarize documents that exceed this token limit, you have to break them into smaller chunks, ensure each chunk fits within the token limit, send each chunk to the model, and then piece together the summaries. This process can become quite cumbersome for very long documents. Here's where Langchain comes to the rescue, automating this task, and we'll explore exactly how it accomplishes this.
Langchain: A Framework for Building LLM Apps
Langchain is a framework for developing applications powered by language models. It is available in both Python and Java Script/Type Script. The power of Langchain comes from its various abstraction of components like Large Language Models, Document Loaders, Prompts, Vector Stores, Tools, Text splitters, Output parsers, Chains, etc. You can learn more about them from their docs here. In this blog, while we are building the document summarizer we will see a few of them like the document loaders, text splitters, chains, etc.
Langchain is built around Large Language Models (LLMs) and provides a set of tools and services to help developers create and deploy NLP applications. It can be used for various purposes such as chatbots, Generative Question-Answering (GQA), summarization, and yeah, It is as interesting as it sounds.
Langchain is very easy to install using pip in Python as shown below
pip install langchain
About OpenAI and Its API
OpenAI is a company founded in 2015 with a mission to make artificial general intelligence (AGI) that benefits everyone. They're known for creating advanced AI models, like GPT-3, which can understand and generate human-like text.
OpenAI also offers its AI technology through an API, so developers can use it in apps and services. We are going to use that API for making this summarization application. We are going to create an account on OpenAI’s website and Generate an API key which we are going to use for our summarizer app.
If you already have an API Key then you can skip the below section.
Steps to Create an OpenAI API Key
If you don’t have an account navigate to the OpenAI Website.
Here, you will see a "Get Started" button at the top right corner of the website. It will open a new tab where you can use any of the given options to create the account.
Click on your preferred option and create an account. After successfully creating an account you will be redirected to the below page
Now click on Personal in the top right corner which will give more options as shown below. Click on View API Keys.
You will see something like below
Click on Create new secret key to generate a new API Key. You will get a pop where you have to give a name to that key just to remember why you created that key which is totally optional. Then, click on create secret key.
Then you have your key, copy it because as it says we can’t see it again. Keep the key somewhere safe, we will use it again when we start coding with Langchain. After creation, it will be listed in the API Key as shown below.
Note that if you are a new user, you will get free $5 or $18 credits which you can see by clicking on the usage section on the left side. If you are an existing user or your credits have already expired then you need to start a payment plan which you can find in the Billing section on the left.
Now that we have the API Key, we are all set and ready for the code.
Summarization in Langchain
The token limit challenge we face with Chat GPT remains, but Langchain offers a smart solution. We can automate the process of breaking down large documents into smaller chunks, summarizing each chunk, and then creating a summary of those summaries. In Langchain, there are two main methods we're interested in for generating these summaries:
Stuff Chain: This is a straightforward approach. We simply gather all the content from the document, put it into a single prompt, and send it to the Large Language Model (LLM).
Map Reduce Chain: Here, we break the document into chunks during the "Map" phase and summarize each chunk. Then, during the "Reduce" phase, we summarize these individual chunk summaries to generate the final summary.
Let's explore these two chains in more detail to see how they work their magic.
Stuff Documents Chain
This is very similar to what we are doing in the chat gpt. We just put all the content of the document into a single prompt and send that prompt to the GPT API. Nothing more than that here. But, we are going to use this when we build our Map Reduce Chain.
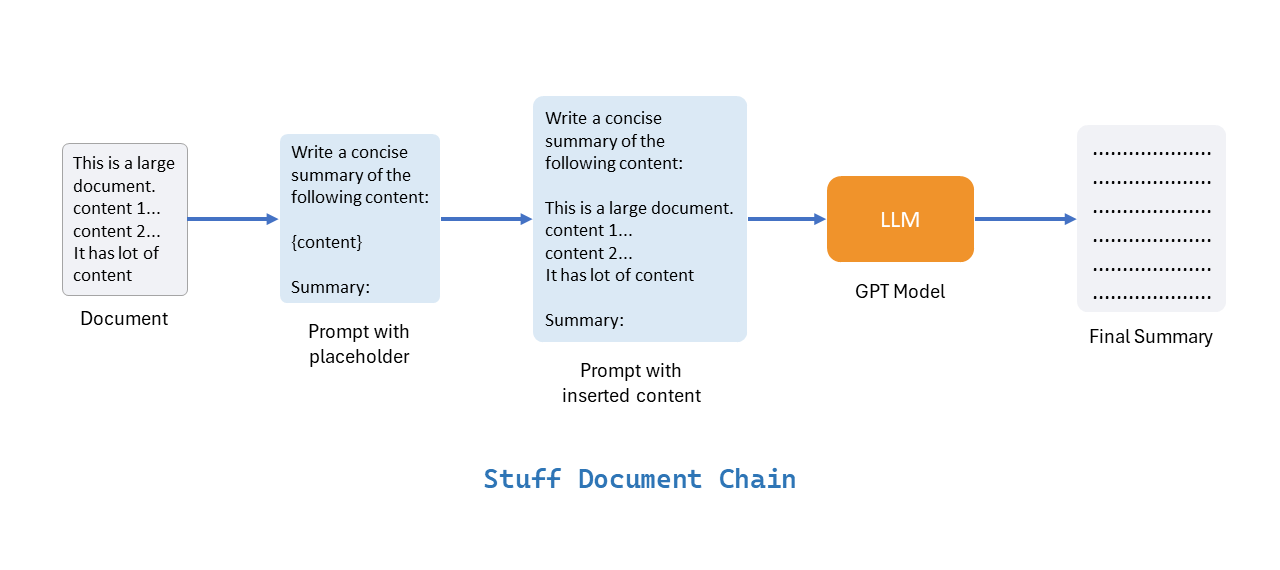
In the figure above, you'll notice we have a prompt that includes a special placeholder for the content. This clever setup allows us to reuse the same prompt structure while just swapping out the specific content we need. We take all the information from the document and insert it directly into the prompt where the placeholder is, and then we send this to a powerful language model like GPT 3.5. This model does its magic and gives us the summary we're looking for. However, there's still a catch – even after we insert the content, the prompt's length should be less than about 4,000 tokens, which means our problem of token limits isn't completely solved yet. Still, let's see how we can build the Stuff Documents Chain in Python using Langchain.
Open your favorite text editor and create a python file. Make sure that Langchain is already installed using pip. You can also run the below command in your terminal to install Langchain
pip install langchain
First, let's create our prompt template.
from langchain.prompts import PromptTemplate
prompt_template = """Write a concise summary of the following content:
{content}
Summary:
"""
prompt = PromptTemplate.from_template(prompt_template)
Here first, we import the PromptTemplate class from the Langchain. prompt_template is a string in which the placeholder will be within the curly braces. Then, we convert that string into a PromptTemplate object which will be used further. With this our prompt is ready.
Now, Let's create the LLM.
Since this LLM is a GPT model from Open AI, we need to set up a few things before we create our LLM. To set up for the GPT Model, we have to install the openai module using pip.
pip install openai
Then, It's time to use the API key which we generated earlier. create a .env file in the working directory and place your API key with the variable OPENAI_API_KEY . The .env file should look something like this

Once you are done with the installing openai module and the OPENAI_API_KEY env variable. We are ready to create our LLM.
Creating the LLM is as simple as shown below
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
But this ChatOpenAI Class still doesn’t have access to the API Key. For that, we need to load our environmental variable here. In order to achieve this, we can just install a module called python-dotenv using pip.
pip install python-dotenv
from the above module, we can a load_dotenv() function that do the trick for us. Now, the code should look like below.
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI()
Now we have our prompt template and also our llm. It’s time to combine those two components. This is where one more component called Chains in Langchain helps us. In Langchain, We define a Chain very generically as a sequence of calls to components.
Chains allow us to combine multiple components together to create a single, coherent application. For example, we can create a chain that takes user input, formats it with a PromptTemplate, and then passes the formatted response to an LLM. We can build more complex chains by combining multiple chains together, or by combining chains with other components.
This is exactly what we are going to do. We will use a chain called LLMChain which will combine the components that we just created. We can provide our prompt template and our LLM. The chain will be the user input and it will insert it into the template and provide the formatted prompt to the LLM.
from langchain.chains import LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm)
We just imported the LLMChain and provided our other two components here.
Now we are just a few lines of code away from our stuff documents chain.
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
stuff_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="content"
)
So, we imported the StuffDocumentsChain and provided our llm_chain to it, as we can see we also provide the name of the placeholder inside out prompt template using document_variable_name, this helps the StuffDocumentsChain to identify the placeholder.
We are ready to use our StuffDocumentsChain. All we need to do is to load some document. If you are wondering how can we load any document then, don’t worry Langchain again comes to the rescue.
Langchain provides a way to load documents from the web.
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(
'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/')
docs = loader.load()
Just like that we loaded a website content about prompt engineering. Since we are loading content from the website Langchain use Beautiful Soap under the hood so you might need to install it
pip install bs4
Let's finally use out stuff document chain to summarize the website’s content.
summary = stuff_chain.run(docs)
print(summary)
When you run the above code it will throw an error as shown below which is totally expected.

If you change the url to some other website which have smaller content and it will work. You can also tweek the prompt by saying “Write a concise summary and output as bullet points” which will provide the summary in key points.
After changing the url to https://python.langchain.com/docs/get_started/introduction this website and tweeking the prompt little bit this how my code looks like
from langchain.document_loaders import WebBaseLoader
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
from langchain.prompts import PromptTemplate
prompt_template = """Write a concise summary of the following content
provide the output in bullent points:
{content}
Summary:
"""
prompt = PromptTemplate.from_template(prompt_template)
load_dotenv()
llm = ChatOpenAI()
llm_chain = LLMChain(prompt=prompt, llm=llm)
stuff_chain = StuffDocumentsChain(
llm_chain=llm_chain, document_variable_name="content")
loader = WebBaseLoader(
'https://python.langchain.com/docs/get_started/introduction')
docs = loader.load()
summary = stuff_chain.run(docs)
print(summary)
Output after running above code:

Now let’s focus on the issue with the tokens and resolve it using our Map Reduce Chain.
Map Reduce Chain
In this approach, we break the document into smaller pieces and use the map-reduce chain for summarization. It's as simple as it sounds: we have two steps. First, we summarize each chunk individually, which is the "map" step. Then, we take these individual summaries and combine them into one final summary, known as the "reduce" step.
Here's a visual representation of what I've just explained:
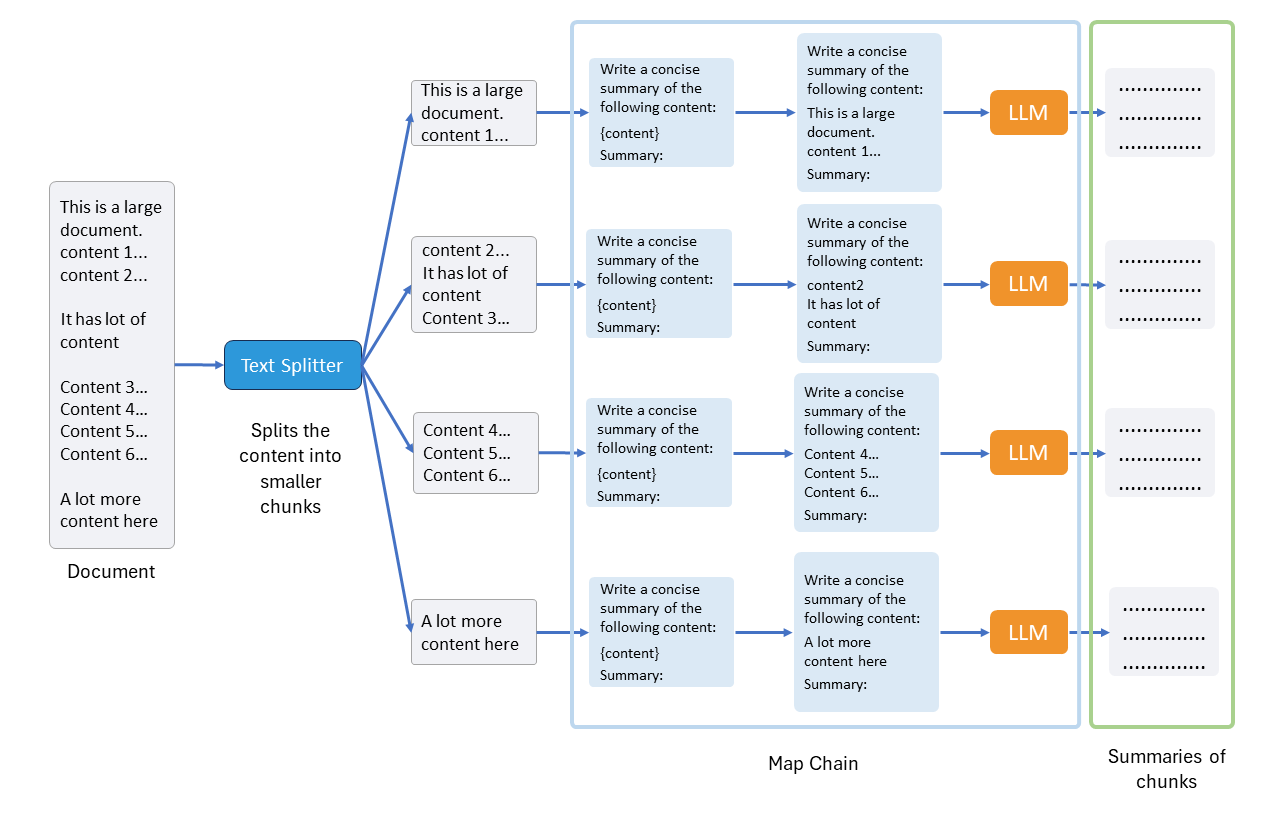
The map chain is just the normal LLMChain which we have already seen earlier. We call the map chain on each chunk and produce its summary. Below we can see the next step:
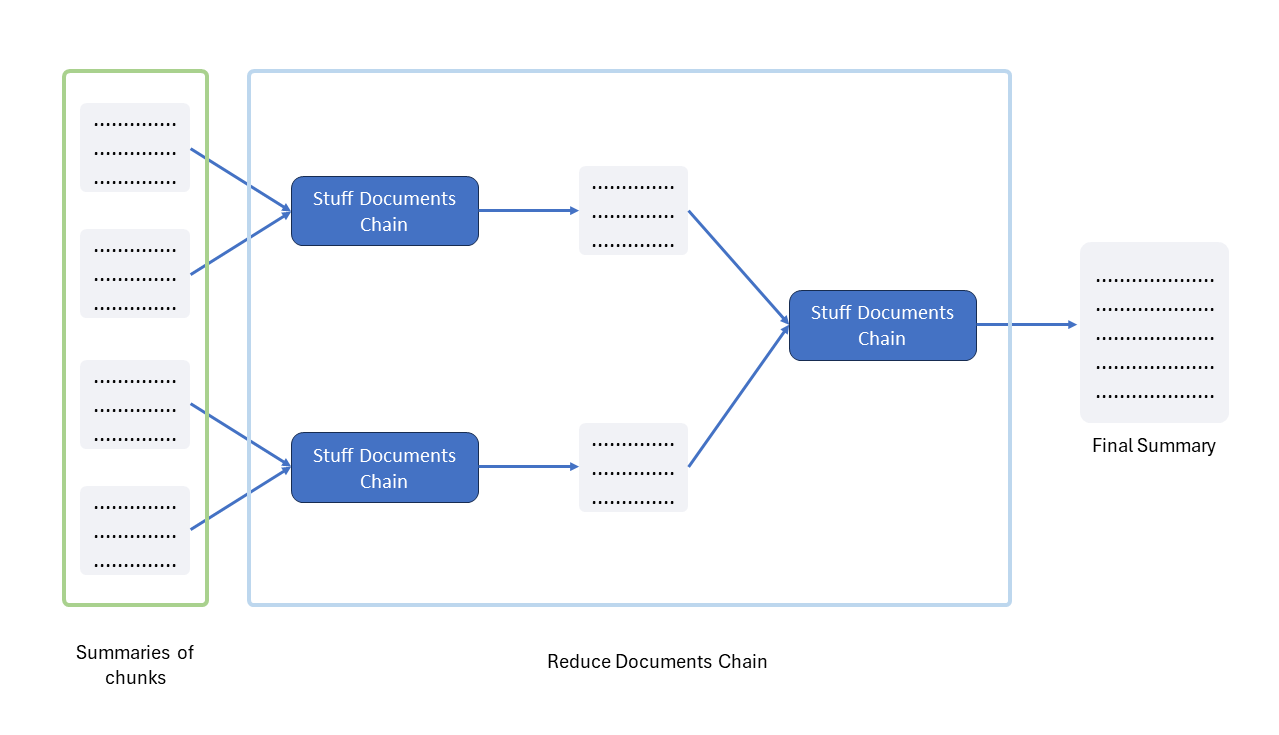
In the "Reduce Documents Chain," there's a smart strategy in play. If we try to combine all the summaries from the chunks in one go, we might still run into the token limit issue. This is because individual summaries are usually smaller than the token limit, but when combined, they can exceed it. So, in this chain, we ensure that the summaries of the chunks we combine remain within the token limit. How? We do it step by step, iteratively reducing the chunks until we get our final summary. It's important to note that we're using the StuffDocumentsChain, which we discussed earlier, in this "reduce" step once again.
Now that we understand how it works. Let's dive into coding
Create another file for this method. Let's start with creating the map chain. As I said, it's just a normal LLMChain that combines the PromptTemplate component and the LLM Component.
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from dotenv import load_dotenv
map_template = """Write a concise summary of the following content:
{content}
Summary:
"""
map_prompt = PromptTemplate.from_template(map_template)
load_dotenv()
llm = ChatOpenAI()
map_chain = LLMChain(prompt=map_prompt, llm=llm)
In the above code snippet we can see, I defined the prompt template for the map_chain and a llm which I combined using a LLMChain.
With that, we are done with our first step. In the second step, we are using StuffDocumentsChain inside the ReduceDocumentsChain. So, Let's create the StuffDocumentsChains as we did in the previous section and then use it to build ReduceDocumentsChain.
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
reduce_template = """The following is set of summaries:
{doc_summaries}
Summarize the above summaries with all the key details
Summary:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
reduce_chain = LLMChain(prompt=reduce_prompt, llm=llm)
stuff_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="doc_summaries")
As usual, we imported the StuffDocumentsChain, created a template for the reduce chain which will used during the reduce step. We created a reduce chain which is also an LLMChain and passed it to the StuffDocumentsChain just like we did earlier. We also provided the name of the placeholder in the template through the document_variable_name which helps the StuffDocumentsChain to identify where to insert the document summaries.
Now, Let's use this stuff_chain in the ReduceDocumentsChain.
from langchain.chains import ReduceDocumentsChain
reduce_chain = ReduceDocumentsChain(
combine_documents_chain=stuff_chain
)
It is as simple as that. We provided our StuffDocumentsChain to the ReduceDocumentsChain.
We also have the option to set a maximum token length, which determines how many summaries to include in the reduce step. It's crucial to ensure that this value remains below the token limit provided by the Large Language Model (LLM) provider.
reduce_chain = ReduceDocumentsChain(
combine_documents_chain=stuff_chain,
token_max=3000
)
The default value is 3000. We can change this value based on the llm provider.
With both our map_chain and reduce_chain in place, we're just a few lines of code away from putting together our map_reduce_chain. Let's go ahead and bring it to life.
from langchain.chains import MapReduceDocumentsChain
map_reduce_chain = MapReduceDocumentsChain(
llm_chain=map_chain,
document_variable_name="content",
reduce_documents_chain=reduce_chain
)
In this step, we've brought in the MapReduceDocumentsChain module and plugged in both our map_chain and the placeholder name within it. And, to complete the picture, we've connected it with our reduce_chain. Voilà! Our map_reduce_chain is now ready to work its magic.
Now, our next step is straightforward. We just need to load the document, break it into smaller, token-compliant chunks, and then feed these chunks into our trusty map_reduce_chain. We've already learned how to fetch content from the web, so now let's focus on creating the text splitter to prepare our document for the summarization process.
from langchain.text_splitter import TokenTextSplitter
splitter = TokenTextSplitter(chunk_size=2000)
split_docs = splitter.split_documents(docs)
Thanks to Langchain, splitting the document has become a breeze. In our process, we've brought in the TokenTextSplitter module, which handles the task of breaking down the loaded document into smaller, more manageable chunks. Importantly, it ensures that each of these chunks remains under the 2000-token limit. To achieve this, we rely on a crucial module called tiktoken, which assists in accurately calculating the token count within our documents. Install it using the below command:
pip install tiktoken
Now we are good to go, Let's provide those split_docs to the map_reduce_chain and see the output.
summary = map_reduce_chain.run(split_docs)
print(summary)
The Final Code should look something like below:
from langchain.text_splitter import TokenTextSplitter
from langchain.chains import MapReduceDocumentsChain
from langchain.chains import ReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.document_loaders import WebBaseLoader
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from dotenv import load_dotenv
# Map Chain
map_template = """Write a concise summary of the following content:
{content}
Summary:
"""
map_prompt = PromptTemplate.from_template(map_template)
load_dotenv()
llm = ChatOpenAI()
map_chain = LLMChain(prompt=map_prompt, llm=llm)
# Reduce Chain
reduce_template = """The following is set of summaries:
{doc_summaries}
Summarize the above summaries with all the key details
Summary:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
reduce_chain = LLMChain(prompt=reduce_prompt, llm=llm)
stuff_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="doc_summaries")
reduce_chain = ReduceDocumentsChain(
combine_documents_chain=stuff_chain,
)
# Map Reduce Chain
map_reduce_chain = MapReduceDocumentsChain(
llm_chain=map_chain,
document_variable_name="content",
reduce_documents_chain=reduce_chain
)
# Load Content from web
loader = WebBaseLoader(
'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/')
docs = loader.load()
# Split the content into smaller chuncks
splitter = TokenTextSplitter(chunk_size=2000)
split_docs = splitter.split_documents(docs)
# Use Map reduce chain to summarize
summary = map_reduce_chain.run(split_docs)
print(summary)
The output after running the above code:

Now, we can successfully summarize the website that previously posed a challenge. I've also taken note of the time required for the program to summarize the text from that link, which was approximately 30 seconds, although it might vary in your case. For further improvements and tailored results, you can fine-tune the prompt templates for both the map_chain and reduce_chain. For detailed insights and guidance, I recommend checking out the official Langchain documentation.
Conclusion
We've delved into the challenges of summarizing lengthy documents.
We've walked through the process of generating an API key from OpenAI.
We've explored and gained an understanding of two distinct summarization methods.
Lastly, we've put these methods into action by implementing both the "Stuff" and "Map-Reduce" techniques using Langchain, a versatile Python framework tailored for developing applications powered by Large Language Models (LLMs).
Thanks for Reading
If you've made it this far, I truly appreciate you taking the time to read my first blog. I hope you found it valuable. Since this is my debut, I'm open to any suggestions or feedback for improvement. If you encounter any challenges while trying out the steps outlined above, please don't hesitate to share them in the comments section. Your input is highly valued!


